




腾讯音乐娱乐的Lyra实验室推出了一项革命性技术——MuseTalk。这款基于潜在空间修补技术的实时高质量唇同步模型,旨在重新定义虚拟人类交互的标准。
MuseTalk的技术背景
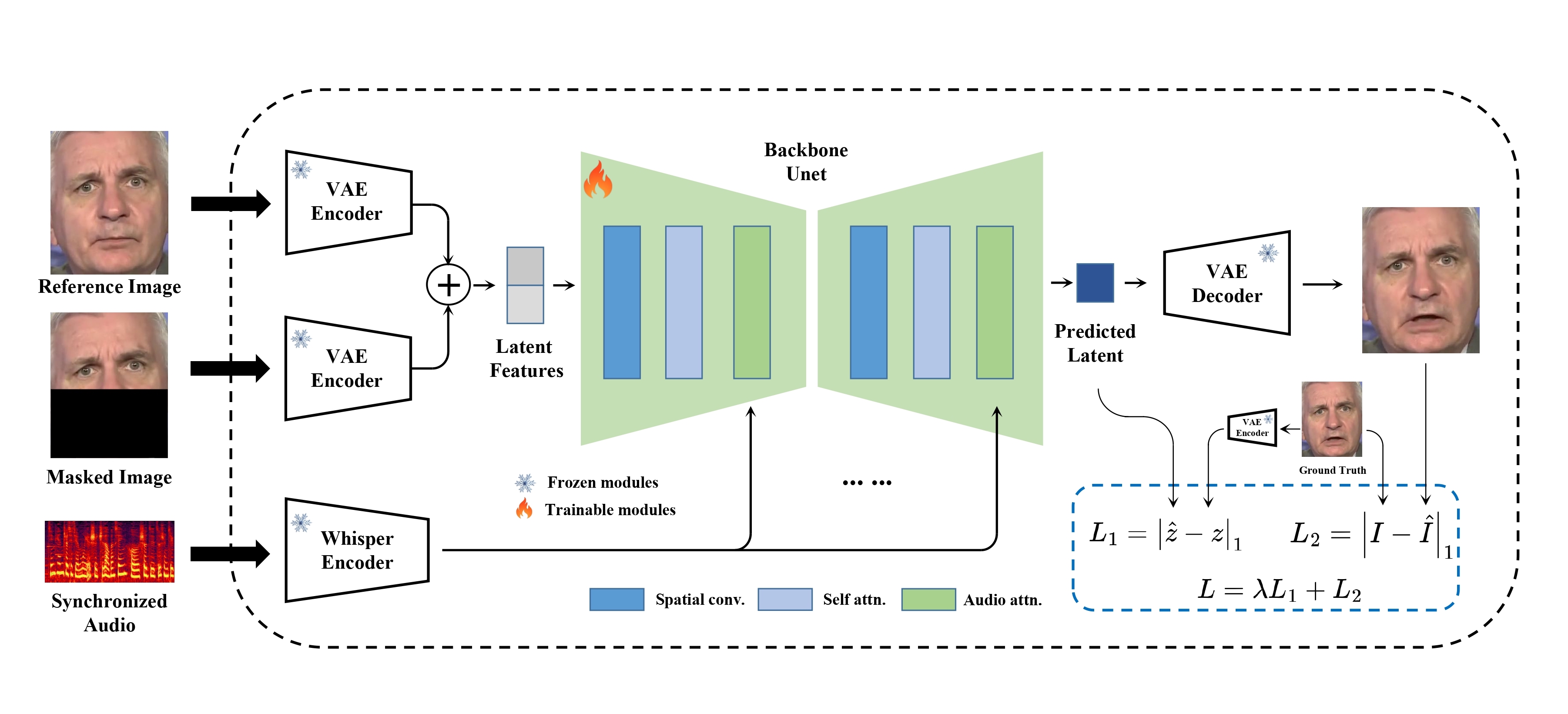
MuseTalk基于先进的机器学习技术,使用改进版的Stable Diffusion V1-4架构。该模型在潜在空间中操作,即根据编码的潜在表示直接修改面部特征,而不是操作原始像素。这使得唇同步更加细腻和高保真。系统采用了编码器-解码器设置,图像使用变分自编码器(VAE)编码,音频则使用OpenAI的Whisper-tiny模型进行编码。
主要特点
- 实时性能:MuseTalk在NVIDIA Tesla V100 GPU上提供每秒30帧以上的实时唇同步性能,非常适合直播应用。
- 高质量:模型生成的唇同步输出在面部区域的分辨率达到256x256像素。
- 多语言支持:支持包括中文、英语和日语在内的多种语言,应用范围广泛。
- 自定义:用户可以调整面部区域的中心点,以影响生成结果,提供输出的灵活性。
实际应用
MuseTalk旨在与其他虚拟人类生成工具如MuseV和MusePose无缝协作,形成一个完整的虚拟人类解决方案。
与MuseV和MusePose的集成
MuseV可以从文本、图像或姿态生成视频,这些视频可以通过MuseTalk增强以添加逼真的唇同步效果。MusePose进一步增加了全身运动和互动层,使得这三个工具形成一个强大的虚拟人类创作套件。
实时推理
MuseTalk的实时推理能力值得注意。预处理步骤如人脸检测和解析在推理过程中提前完成,使得模型在推理期间只需专注于唇同步生成。这种优化确保了MuseTalk在直播场景中仍能保持高帧率。
安装和设置
安装MuseTalk需要准备Python环境并安装若干依赖项,包括opencv、diffusers和mmcv。仓库中提供了详细的安装说明,确保用户能轻松上手。
安装步骤
- 环境设置:推荐使用Python >=3.10和CUDA =11.7。
- 包安装:使用
pip和mim安装必要的软件包。 - 下载权重:用户需手动从HuggingFace和其他来源下载预训练权重。
- 配置:根据提供的YAML配置文件进行路径和设置的配置。
使用场景
MuseTalk可应用于多种场景,包括:
- 视频配音:自动同步配音音频和视频,提升观看体验。
- 虚拟主播:创建逼真的虚拟主播,实时与观众互动。
- 游戏:通过提供基于游戏内对话的真实唇部动作,增强角色动画。
案例研究
多个案例研究展示了MuseTalk的能力。例如,将MuseV和MuseTalk结合使用,可以使Elon Musk等名人的静态照片栩栩如生,创造出互动性强的内容。
限制与未来方向
尽管MuseTalk取得了显著进展,但仍有一些限制。目前的分辨率为256x256像素,虽然高,但还不是理论最高值,未来会继续改进。此外,某些身份保留问题(如胡须和唇部细节的保持)需要进一步优化。
未来的开发将针对这些限制进行改进,计划提升分辨率并引入更强大的身份保留技术。路线图还包括发布训练代码和详细的技术报告。
数智朋克点评
MuseTalk在实时唇同步领域取得了重大突破。通过利用潜在空间修补技术并与其他虚拟人类生成工具集成,它为创建逼真互动的数字化身提供了一个多功能且强大的解决方案。无论是在娱乐、教育还是商业应用中,MuseTalk都为AI驱动的内容创作开辟了新的可能性。

 粤公网安备44030002001270号
粤公网安备44030002001270号