




人类天生就是多模态生物,听觉与视觉往往是我们感知世界的重要途径。然而,传统的计算机视觉任务,尤其是目标分割,大多数仅限于纯视觉信号,忽略了听觉线索的辅助作用。这在现实世界中显然是个巨大缺陷。无论是看电视节目,还是在街上寻找方向,我们几乎从未孤立地依赖视觉或听觉中的任何一种。
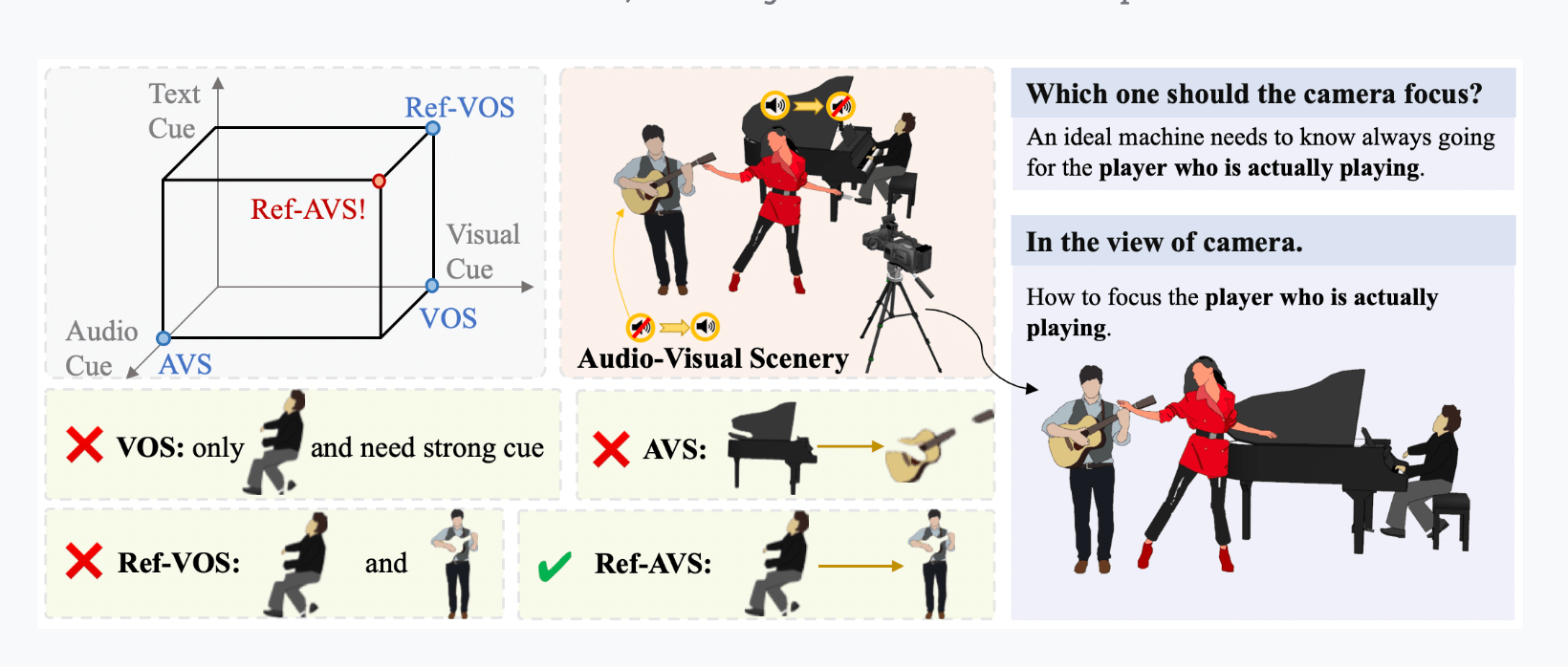
Ref-AVS是什么?
Ref-AVS,全称是“Refer and Segment Objects in Audio-Visual Scenes”,这一任务的诞生正是为了填补这一空白。它引入了一个革命性的思路:让机器能够像人类一样,基于多模态线索进行物体定位和分割。这不仅要求算法在视觉上“看到”物体,还要求它能“听到”相应的音频线索,从而做出更准确的判断。
数据集的构建
为了推动这一研究,Ref-AVS项目团队构建了首个Ref-AVS基准数据集。这一数据集包含多达48个类别、4,002个视频和40,020帧图像,并且对每个目标进行了像素级别的精确标注。这些数据来自多种场景,从人类活动到音乐演奏,再到动物活动,涵盖了多种复杂的现实场景。通过这样的数据集,算法可以学习如何在多样化、动态化的场景中识别并定位目标。
技术背后的团队
Ref-AVS项目由中国人民大学、北京邮电大学以及上海人工智能实验室的研究人员共同开发,汇聚了多个领域的专家。这些团队的共同努力,确保了数据集的高质量与多样性,并为多模态分割算法的开发提供了坚实的基础。
应用前景与挑战
从长远来看,Ref-AVS不仅仅是一个研究项目,它更代表了多模态AI的未来趋势。在现实应用中,这样的技术可以被应用到智能安防、自动驾驶、视频内容分析等多个领域。然而,挑战仍然存在——如何进一步提升多模态信息的融合效果,如何在更复杂的场景中保持高效分割能力,都是未来研究的重点方向。
数智朋克点评
Ref-AVS作为多模态分割领域的新突破,展示了其强大的技术潜力和广泛的应用前景。然而,如何将其从实验室推进到实际应用场景中,仍然是研究人员面临的一大课题。总的来说,这一研究为音视多模态融合开辟了新的路径,也为未来的AI发展指明了方向。

 粤公网安备44030002001270号
粤公网安备44030002001270号